The goal of this project was to take a middleware particle effect and optimize it as much as possible. It also doubled as a class-wide competition to see who could squeeze the most performance out of it.
In the video below, you can see a (very) short demonstration of the side-by-side visual output and timings for my optimized version and the original baseline version, with the program’s run-time parameters set at 20k total particles and a 17 second loop.
I really, really enjoyed this project.
I pored over my past assignments and notes. I scrutinized every formula. I walked through the code line-by-line. I used every ounce of knowledge that I had to take this puzzle apart and piece it back together. In the end, I was able to achieve a significant increase in performance compared to the baseline program.
Below are a few areas of improvement I was able to identify and address, in mostly chronological order (based on when a particular alteration was made). While each listed adjustment was beneficial, there were three that were especially impactful, and are highlighted below.
- Properly defining the Big Four across every class, either by default, delete, or user specified
- Moving variable initializations to the init list whenever possible
- Making use of ‘const’ in both function signatures and parameters
- Altering many function parameters to be pass-by-reference instead of pass-by-value
- Converting all Doubles to Floats
- Converting temporaries into members, global statics, or removing them entirely
- Converting the original STL List of Particles into a standard array, which:
- Eliminated constant resizing and reallocation of the List
- Removed all particle constructors beyond the initial run-time set up, and all particle destructors outside of closing the program
- Allowed me convert loops using pointers and iterators to simple indexed for-loops
- Simplifying and reducing operations inside functions and loops as much as possible, eliminating many of them altogether
- Facilitating compiler-led optimization by ensuring 16-byte alignment for objects frequently used in arithmetic operations (specifically for SIMD)
- Reducing the size of objects for improved caching—specifically, reducing the size of a single Particle object from 512 bytes to 112 bytes
- This allowed me to further split Particles into Hot (48-byte) and Cold (64-byte) structs, as many loops involved Particles, but only a single loop required the Matrix transform which became the Cold struct
- Adjusting functions to make use of RVO, especially for Vector and Matrix arithmetic
- Identifying a number of Matrix elements that were uniformly set to 0.0f for the every Particle, allowing me to eliminate a substantial amount of operations
- I was fortunate enough to be taking Applied 3D Geometry concurrently with this course, which was massively helpful when it came to reducing—and ultimately eliminating—the GetAdjugate(), Inverse(), and Determinant() functions
- Substituting in SIMD intrinsics for certain complex arithmetic operations
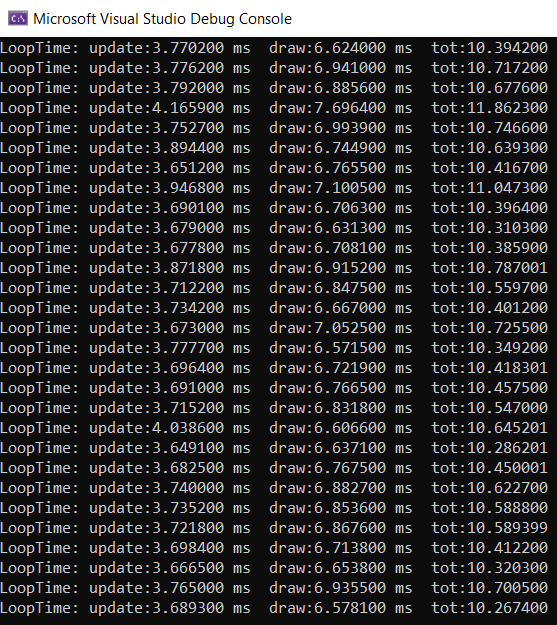
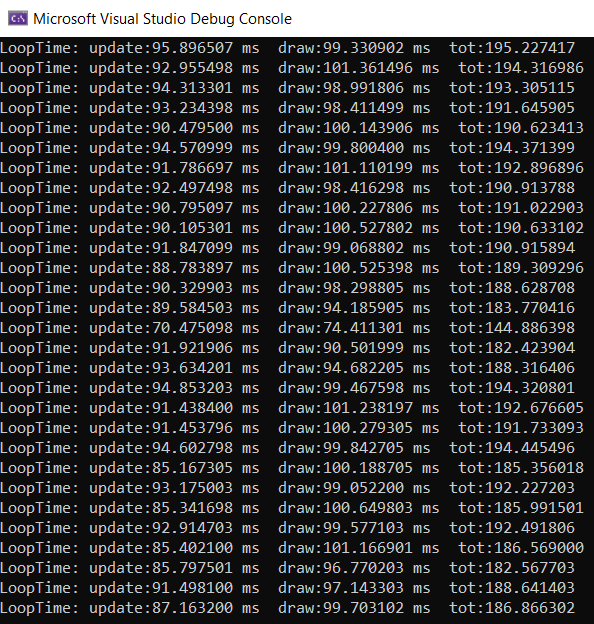
Here are the full testing results when running the program at the intended volume of 300k particles for a full 17 second loop.
TESTING
Sample Size
Baseline: 267 output loops
Optimized: 279 output loops
Test Settings
Number of Particles — 300k
Loop Duration — 17 seconds
Update() Time
Baseline: 85.43086111 ms
Optimized: 3.814734409 ms
Delta: -81.6161267 ms
Improvement: 22.3949696 times faster
Draw() Time
Baseline: 99.40260173 ms
Optimized: 6.82981972 ms
Delta: -92.57278201 ms
Improvement: 14.55420579 times faster
Total Time
Baseline: 184.8334631 ms
Optimized: 10.6445542
Delta: -174.1889089 ms
Improvement: 17.36413377 times faster
Sample Results
Optimized
Baseline
Class Contest Results
Victory.

Note: The actual testing computer was faster than my own, with better results
